Have you ever wanted to fine-tune a large language model, but didn’t have the time or resources to train it from scratch? In this post, I’ll show you how to use adapter-transformers to fine-tune Flan-T5 on the XSum dataset in five minutes. I’ll also show you how to use the resulting model to generate summaries for any text.
What is Fine-Tuning?
Fine-tuning is the process of training a pre-trained model on a new dataset. This usually takes less time than training a model from scratch, but it can still take a long time.
What is adapter-transformers?
adapter-transformers is a library for fine-tuning transformers, based on HuggingFace’s transformers library. It has a number of new features that make it easier to fine-tune transformers, such as LoRA (Low Rank Adaptation), which allow you to reduce the amount of parameters that need to be trained.
What is LoRA?
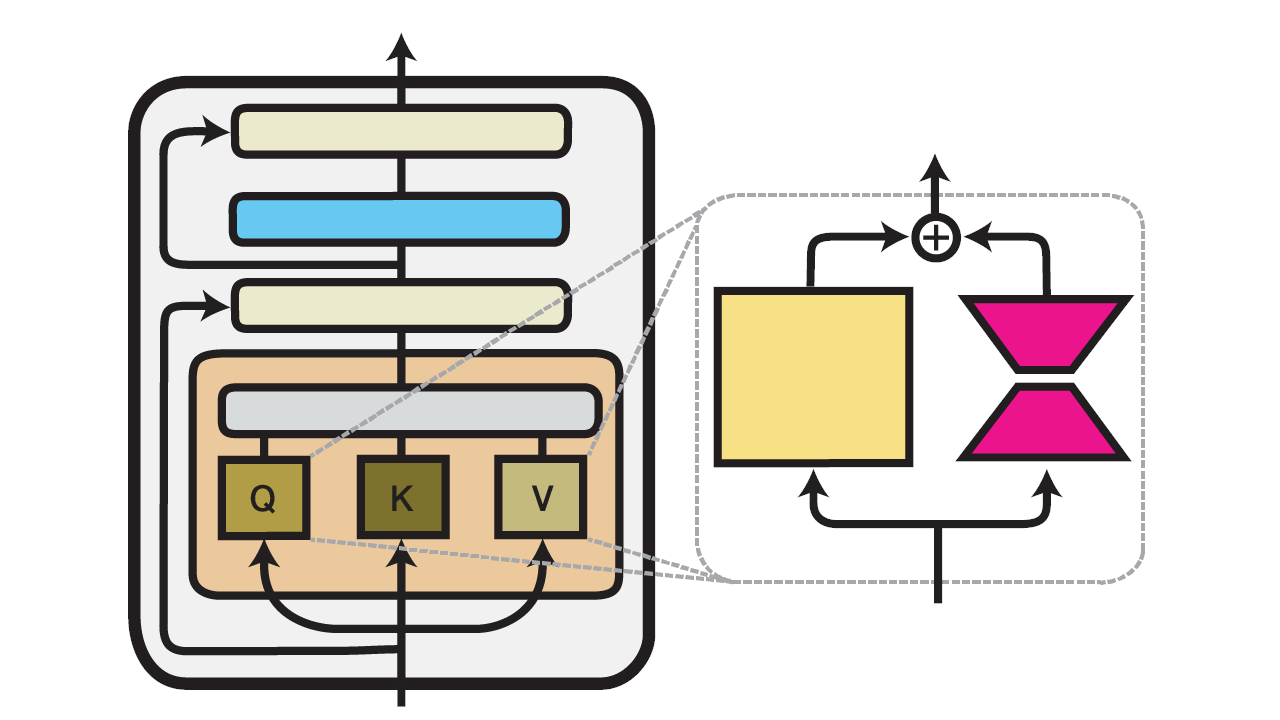
LoRA works by training two small matrices that are multiplied together to produce a large matrix. This large matrix is then added to the pre-trained model’s weights, usually in the attention layers. Adding the matrices is equivalent to adding the results of the matrix multiplication, which is done in training.
The Flan-T5 Model
Flan-T5 is a series of models by Google that are based on the T5 architecture. They are text-to-text transformers that can be used for a variety of tasks, making them a great starting point for fine-tuning.
In this post, I’ll be using flan-t5-base, which is one of the smaller models in the series.
The XSum Dataset
XSum stands for Extreme Summarization and is a dataset of documents and summaries.
In this post, I’ll be using a small subset of the XSum dataset, which contains 1,000 documents and their summaries.
Environment Setup
I’ll be using Google Colab for this post, but you can also run it locally if you have a GPU and the necessary libraries installed.
To install the libraries that aren’t installed in Google Colab, you’ll have to run the following commands:
pip install -U adapter-transformers sentencepiece
pip install datasets
Tokenizing the Dataset
In order to use the Flan-T5 model, we’ll have to convert the documents and summaries into tokens that the model can understand.
To do this, we’ll use the AutoTokenizer class from the transformers library. We’ll also use a prefix before the documents, which is used by the model to determine what task it should perform. In this case, the prefix is “summarize: ”. We have to do this because this is the format the model expects.
from transformers import AutoTokenizer
# the base model that we'll be using
base_model = "google/flan-t5-base"
# the tokenizer that we'll be using
tokenizer = AutoTokenizer.from_pretrained(base_model)
# the prefix that we'll be using
prefix = 'summarize: '
# tokenize the dataset
def encode_batch(examples):
# the name of the input column
text_column = 'document'
# the name of the target column
summary_column = 'summary'
# used to format the tokens
padding = "max_length"
# convert to lists of strings
inputs, targets = [], []
for i in range(len(examples[text_column])):
if examples[text_column][i] and examples[summary_column][i]:
inputs.append(examples[text_column][i])
targets.append(examples[summary_column][i])
# add prefix to inputs
inputs = [prefix + inp for inp in inputs]
# finally we can tokenize the inputs and targets
model_inputs = tokenizer(inputs, max_length=512, padding=padding, truncation=True)
labels = tokenizer(targets, max_length=512, padding=padding, truncation=True)
# rename to labels for training
model_inputs["labels"] = labels["input_ids"]
return model_inputs
Loading the Dataset
We’ll be using the datasets library to load the dataset, and we will load a subset of the dataset from each split.
from datasets import load_dataset
# load the dataset
def load_split(split_name, max_items):
# load the split
dataset = load_dataset("xsum")[split_name]
# only use the first max_items items
dataset = dataset.filter(lambda _, idx: idx < max_items, with_indices=True)
# tokenize the dataset
dataset = dataset.map(
encode_batch,
batched=True,
remove_columns=dataset.column_names,
desc="Running tokenizer on " + split_name + " dataset",
)
# set the format to torch
dataset.set_format(type="torch", columns=["input_ids", "labels"])
return dataset
Preparing the Model
Now that we have the dataset, we can prepare the model for training.
from transformers import AutoModelForSeq2SeqLM
from transformers.adapters import LoRAConfig
import numpy as np
# start with the pretrained base model
model = AutoModelForSeq2SeqLM.from_pretrained(
base_model
)
# set the parameters for LoRA
config = LoRAConfig(
r=8,
alpha=16,
# use it on all of the layers
intermediate_lora=True,
output_lora=True
)
# make a new adapter for the XSum dataset
model.add_adapter("xsum", config=config)
# enable the adapter for training
model.train_adapter("xsum")
model.set_active_adapters(["xsum"])
Preparing the Trainer
Now that we have the model, we can prepare the trainer.
from transformers import TrainingArguments, AdapterTrainer, TrainerCallback
# small batch size to fit in memory
batch_size = 1
training_args = TrainingArguments(
learning_rate=3e-4,
num_train_epochs=1,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
logging_steps=200,
output_dir="./training_output",
overwrite_output_dir=True,
remove_unused_columns=False
)
# create the trainer
trainer = AdapterTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
# load the dataset
train_dataset=load_split("train", 1000),
eval_dataset=load_split("test", 100),
)
Training the Model
Now that we have the trainer, we can train the model. This will take a while, especially depending on your hardware.
trainer.train()
Evaluating the Model
Now that we have the trained model, we can evaluate its performance on the test split.
trainer.evaluate()
Merging the Adapters
Like I mentioned earlier, we will need to add the matrices.
# merge the adapter with the model
# this will add the adapter weight matrices to the model weight matrices
model.merge_adapter("xsum")
Generating Summaries
We will use the validation split of the dataset and compare our summaries with the actual summaries.
num_validation = 10
validation_dataset = load_split('validation', num_validation)
for i in range(num_validation):
# load the input and label
input_ids = validation_dataset[i]['input_ids'].unsqueeze(0).to(0)
label_ids = validation_dataset[i]['labels'].unsqueeze(0).to(0)
# use the model to generate the output
output = model.generate(input_ids, max_length=1024)
# convert the tokens to text
input_text = tokenizer.decode(input_ids[0], skip_special_tokens=True)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
label_text = tokenizer.decode(label_ids[0], skip_special_tokens=True)
print('Input:', input_text)
print('Output:', output_text)
print('Label:', label_text)
print('---')
Saving the Model
Now that we have the trained model, we can save it. Mine is saved to tripplyons/flan-t5-base-xsum.
# login to upload the model
from huggingface_hub import login
login()
from huggingface_hub import HfApi
import torch
api = HfApi()
torch.save(model.state_dict(), 'pytorch_model.bin')
api.upload_file(
path_or_fileobj="pytorch_model.bin",
path_in_repo="pytorch_model.bin",
# replace with your own username in order to upload
repo_id="tripplyons/flan-t5-base-xsum",
repo_type="model",
)
Conclusion
Hopefully this tutorial was helpful in showing how to quickly fine-tune a model for a new task using adapters. My source code for this tutorial can be found on Google Colab.